A few quick thoughts on the news that many published results in psychology can’t be replicated.
First, good for the researchers for doing this!
Second, I’ve read that R.A. Fisher, who was largely responsible for introducing the notion of using p-values to test for statistical significance, regarded the standard 5% level as merely an indication that something interesting might be going on, not as a definitive detection of an effect (although other sources seem to indicate that his views were more complicated than that). In any case, whether or not that’s what Fisher thought, it’s a good way to think of things. If you see a hypothesis confirmed with a 5% level of significance, you should think, “Hmm. Somebody should do a follow-up to see if this interesting result holds up,” rather than “Wow! It must be true, then.”
Finally, a bit of bragging about my own discipline. There’s plenty of bad work in physics, but I suspect that the particular problems that this study measured are not as bad in physics. The main reason is that in physics we do publish, and often even value, null results.
Take, for instance, attempts to detect dark matter particles. No one has ever done it, but the failed attempts to do so are not only publishable but highly respected. Here is a review article on the subject, which includes the following figure:
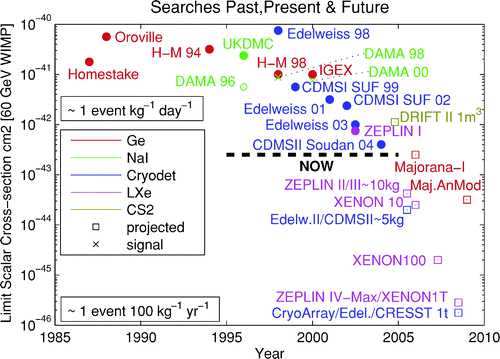
Every point in here is an upper limit — a record of a failed attempt to measure the number of dark matter particles.
I suspect that part of the reason we do this in physics is that we often think of our experiments primarily as measuring numbers, not testing hypotheses. Each dark matter experiment can be thought of as an attempt to measure the density of dark matter particles. Each measurement has an associated uncertainty. So far, all of those measurements have included the value zero within their error bars — that is, they have no statistically significant detection, and can’t rule out the null hypothesis that there are no dark matter particles. But if the measurement is better than previous ones — if it has smaller errors — then it’s valued.