Nature has a bunch of feature articles in the current issue on the future of scientific publishing. I was particularly interested in the one called Open access: The true cost of science publishing (possibly paywalled). The idea of “open access” — meaning that people should be able to access scientific publications for free, especially because in many cases their tax dollars funded the research — has been getting a lot of traction lately (and rightly so in my opinion).
If access is free, meaning that libraries no longer have to pay (often exorbitant) subscription costs, then the question naturally arises of who does pay the costs of publishing and disseminating research. One answer is that authors should pay publication costs, presumably out of the same sources of funding that supported the original research. To decide how well that’ll work, you need some sort of notion of what the costs are likely to be. Here’s one answer, from the Nature article:
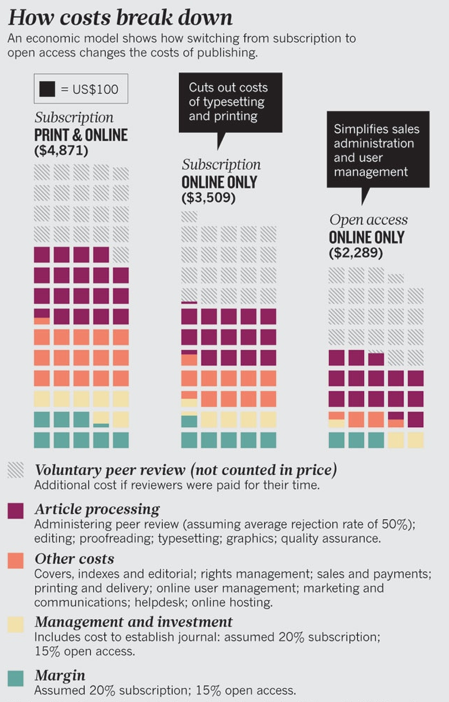
The right column is the one that interests me: suppose that we have open access and publish only online.
The gray boxes at the top represent the cost in referees’ time. Since referees aren’t generally paid, nobody explicitly or directly pays that cost. Not counting that, they estimate a cost of about $2300 per published article, with the biggest chunk (about $1400) coming from “Article processing,”
Administering peer review (assuming average rejection rate of 50%); editing; proofreading; typesetting; graphics; quality assurance.
Let me take these one at a time.
Administering peer review: This is certainly a legitimate expense: although referees are not paid, journals do have paid employees to deal with this. I wouldn’t have guessed that this cost was a significant fraction of $1400, but I have no actual data.
- Editing: The journals I deal with do extremely minimal editing.
- Proofreading: I have to admit, they generally do a good job with this.
- Typesetting: The journal typically converts the LaTeX file I give them into some other format, but (a) it’s not clear to me that they have to do that — the final product isn’t noticeably better than the original LaTeX-formatted document (and is often considerably worse), and (b) surely this is largely automated.
- Graphics: I provide the graphics. The journal doesn’t do anything to them. (In cases where a journal does help significantly with production of graphics, I certainly agree that that’s a service that should be paid for.)
- Quality assurance: I have to punt on this. I don’t know what’s involved.
I have trouble seeing how the sum total of these services is worth $1400 per article. I tried to look in some of the sources cited in the article (specifically, these two) for a more detailed cost breakdown, but I didn’t find anything that helped much.
Peter Coles, who’s been exercised about this for longer than I have, says
Having looked carefully into the costs of on-line digital publishing I have come to the conclusion that a properly-run, not-for-profit journal, created for and run by researchers purely for the open dissemination of the fruits of their research can be made sustainable with an article processing charge of less than £50 per paper, probably a lot less.
I have no idea if he’s right about this, but I do find the thousands-of-dollars-per-paper estimates to be implausible. I mean what I say in the title of this post, though: I just don’t understand the economics here.
Peter proposes to create a new low-cost, not-for-profit, open journal of astrophysics. I hope he does it, and I hope it succeeds (and as I’ve told him I’ll be glad to help out with refereeing, etc.).