As you can see, I’m not posting much on the blog these days, but every once in a while I figure out something that I want to write down so that I can refer my students to it, and this seems like the place to do it. Like a couple of previous posts, this one comes out of the electricity and magnetism course that I teach from time to time.
In his excellent textbook Introduction to Electrodynamics, David Griffiths works out the magnetic field of an infinite solenoid as an example of the application of Ampère’s Law. He shows that the field outside the solenoid is uniform, and then he says it must be zero, because “it certainly approaches zero as you go very far away.” That word “certainly” seems to be hiding something: how do we know that the field goes to zero far away? After all, we’re talking about an infinite solenoid, in which the current keeps going forever. Is it really obvious that the field goes to zero?
(For comparison, think about the electric field caused by an infinite plane of charge. You could imagine saying that that “certainly” goes to zero as you get very far away, but it doesn’t.)
Griffiths’s arguments are usually constructed very carefully, but this is an uncharacteristic lapse. While many students will cheerfully take him at his word, some (particularly the strongest students) will want an argument to justify this conclusion. So here is one. (It’s essentially the same as the one in this document by C.E. Mungan, but I flatter myself that my explanation is a bit easier to follow.)
The argument must be based on the Biot-Savart Law, not Ampère’s Law. The reason is that you can always add a constant vector to the magnetic field in a solution to Ampère’s Law and get another solution. So Ampère’s Law alone can never convince us that the field outside is zero. In some situations like this, you can combine it with a symmetry principle to get around this, but if there is one here I can’t see it. So Biot-Savart it is.
The Biot-Savart Law tells you how to get the magnetic field caused by a given current distribution by adding up (integrating) the contributions from all of the infinitesimal current elements. I want to show that the contributions from certain current elements cancel when you’re calculating the field at a point outside the solenoid. That is, I intend to show that B = 0 everywhere outside the solenoid, not just that it goes to zero far away.
Here’s the key picture.
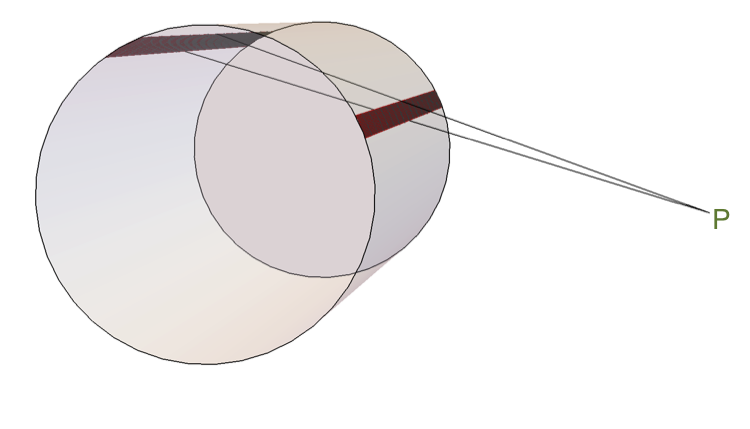
The cylinder is the solenoid. We’re trying to figure out the magnetic field at the point P. The two red bands are two thin strips of the solenoid that subtend the same small angle. I want to show that the contributions to the magnetic field at P from those two strips cancel. Since the whole solenoid can be broken up into pairs of strips like these, that’ll show that B = 0 outside the solenoid.
Here’s the same setup, but showing just a cross section.
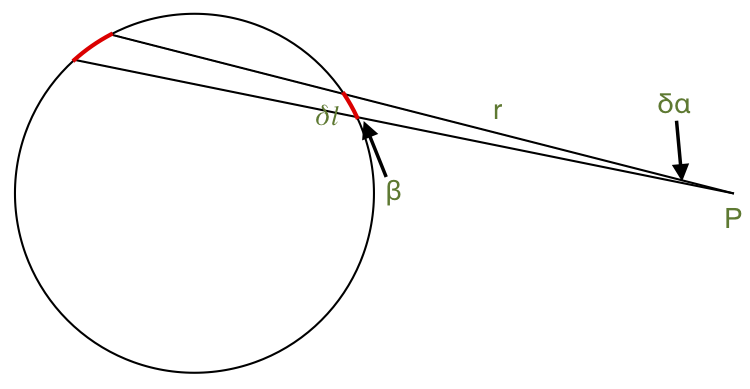
I labeled a couple of angles and lengths in this picture. They apply to the triangle formed by the point P and the closer of the two strips of current.
Here’s the main point:
The contribution to the magnetic field at P due to that strip of current is proportional to δl sin β / r. It points into the screen, straight away from you (assuming the current flows counterclockwise).
You can show that this is true by actually doing the Biot-Savart integral for this strip. The result, unless I’ve made a mistake, is
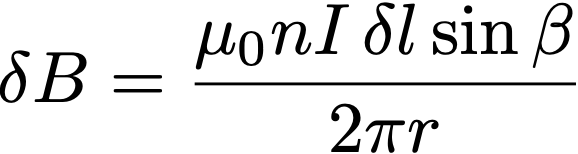
where n is the number of turns per unit length and I is the current.
But you might be able to convince yourself of it without doing the integral. The sin β comes from the cross product in the Biot-Savart law. The amount of current on that strip is proportional to its width δl. The 1/r has to be there on dimensional grounds: B has to be inversely proportional to a distance, and r is the only relevant distance.
The Law of Sines tells us that sin β / r = sin δα / δl, so the magnetic field due to this strip is proportional to sin δα (and none of the other quantities in the diagram). To be specific,

(By the way, since δα is small, it’d be fine to write just δα instead of sin δα.)
Now draw the analogous triangle and do the same thing for the other of the two strips. The answer is exactly the same, except that by the right-hand rule it points the other way. So the two contributions cancel.
By the way, this argument never assumed that the solenoid was a circular cylinder. Its cross section can be any crazy shape, and you’ll always be able to chop it up into pairs of thin strips that cancel in this way.







{kind=link}
{kind=link}