I’ve been programming in IDL for a couple of decades. How did I not know about this bizarre behavior of its random number generator?
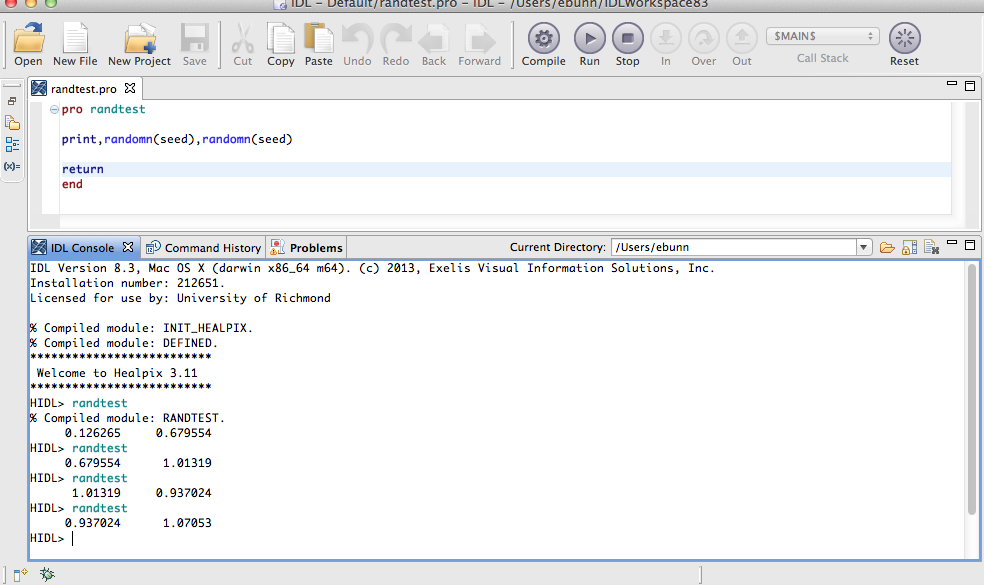
Apparently, this is something people know about, but somehow I’d missed it for all this time.
I’ve been programming in IDL for a couple of decades. How did I not know about this bizarre behavior of its random number generator?
Apparently, this is something people know about, but somehow I’d missed it for all this time.
I’m a little late getting to this, but in case you haven’t heard about it, here it is.
A journalist named John Bohannon did a stunt recently in which he and some coauthors “published” a “study” that “showed” that chocolate caused weight loss. (The reasons for the scare quotes will become apparent.) The work was picked up by a bunch of news outlets. Bohannon wrote about the whole thing on io9. It’s also been picked up in a bunch of other places, including the BBC radio program More or Less (which I’ve mentioned before a few times).
The idea was to do a study that was shoddy in precisely the ways that many “real” studies are, get it published in a low-quality journal, and see if they could get it picked up by credulous journalists.
My colleagues and I recruited actual human subjects in Germany. We ran an actual clinical trial, with subjects randomly assigned to different diet regimes. And the statistically significant benefits of chocolate that we reported are based on the actual data. It was, in fact, a fairly typical study for the field of diet research. Which is to say: It was terrible science. The results are meaningless, and the health claims that the media blasted out to millions of people around the world are utterly unfounded.
There is an interesting question of journalistic ethics here. Bohannon calls himself a journalist, but he deliberately introduced bad science into the mediasphere with the specific intent of deception. Is it OK for a journalist to do that, if his motives are pure? I don’t know.
I don’t want to focus on that sort of issue, because I don’t have anything non-obvious to say. Instead, I want to dig a bit into the details of what Bohannon et al. did. Although Bohannon’s io9 post is well worth reading and gets the big picture largerly right, it’s wrong or misleading in a few ways, which happen to be the sort of thing I care about.
Bohannon et al. recruited a group of subjects and divided them into three groups: a control group, a group that was put on a low-carb diet, and a group that was put on a low-carb diet but also told to eat a certain amount of chocolate each day. The chocolate group lost weight faster than the other groups. The result was “statistically significant,” in the usual meaning of that term — the p-value was below 0.05.
So what was wrong with this study? As Bohannon explains it in his io9 post,
Here’s a dirty little science secret: If you measure a large number of things about a small number of people, you are almost guaranteed to get a “statistically significant” result. Our study included 18 different measurements—weight, cholesterol, sodium, blood protein levels, sleep quality, well-being, etc.—from 15 people. (One subject was dropped.) That study design is a recipe for false positives.
…
The conventional cutoff for being “significant” is 0.05, which means that there is just a 5 percent chance that your result is a random fluctuation. The more lottery tickets, the better your chances of getting a false positive. So how many tickets do you need to buy?
P(winning) = 1 – (1 – p)n
With our 18 measurements, we had a 60% chance of getting some“significant” result with p < 0.05. (The measurements weren’t independent, so it could be even higher.) The game was stacked in our favor.
It’s called p-hacking—fiddling with your experimental design and data to push p under 0.05—and it’s a big problem. Most scientists are honest and do it unconsciously. They get negative results, convince themselves they goofed, and repeat the experiment until it “works.” Or they drop “outlier” data points.
Sadly, even in this piece, whose purpose is to debunk bad statistics, Bohannon repeats the usual incredibly common error. A p-value of 0.05 does not mean that “there is just a 5 percent chance that your result is a random fluctuation.” It means that, if you assume that nothing but random fluctuations are at work, there’s a 5% chance of getting results as extreme as you did. A (frequentist) p-value is incapable of telling you anything about the probability of any given hypothesis (such as “your result is a random fluctuation”).
One other quibble: the parenthetical remark about the measurements not being independent is literally true but misleading. The fact that the measurements aren’t independent means that the probability of a false positive “could be even higher”, but it could also be lower. In fact, the latter seems more likely to me. (The probability goes down if the measurements are positively correlated with each other, and up if they’re anticorrelated.)
The other thing that’s worth focusing on is the number of subjects in the study, which was incredibly small (15 across all three groups). Bohannon suggests (in the first sentence quoted above) that this is part of the reason they got a false positive, and other pieces I’ve read on this say the same thing. But it’s not true. The reason they got a false positive was p-hacking (buying many lottery tickets), which would have worked just as well with a larger number of subjects. If you had more subjects, the random fluctuations would have gotten smaller, but the level of fluctuation required for statistical “significance” would have gone down as well. By definition, the odds of any one “lottery ticket” winning is 5%, whether you have a lot of subjects or a few.
It’s true that with fewer subjects the effect size (i.e., the number of extra pounds lost, on average) is likely to be larger, but the published article went to great lengths to downplay the effect size (e.g., not mentioning it in the abstract, which is often all anyone reads).
Let me repeat that I think that Bohannon’s description of what he did is well worth reading and has a lot that’s right at the macro-scale, even though I wish that he’d gotten the above details right.
In Surely You’re Joking, Mr. Feynman, Richard Feynman tells a story of sitting in on a philosophy seminar and being asked by the instructor whether he thought that an electron was an “essential object.”
Well, now I was in trouble. I admitted that I hadn’t read the book, so I had no idea of what Whitehead meant by the phrase; I had only come to watch. “But,” I said, “I’ll try to answer the professor’s question if you will first answer a question from me, so I can have a better idea of what ‘essential object’ means. Is a brick an essential object?”
What I had intended to do was to find out whether they thought theoretical constructs were essential objects. The electron is a theory that we use; it is so useful in understanding the way nature works that we can almost call it real. I wanted to make the idea of a theory clear by analogy. In the case of the brick, my next question was going to be, “What about the inside of the brick?”–and I would then point out that no one has ever seen the inside of a brick. Every time you break the brick, you only see the surface. That the brick has an inside is a simple theory which helps us understand things better. The theory of electrons is analogous. So I began by asking, “Is a brick an essential object?”
The way he tells the story (which, of course, need not be presumed to be 100% accurate), he never got to the followup question, because the philosophers got bogged down in an argument over the first question.
I was reminded of this when I read A Crisis at the Edge of Physics , by Adam Frank and Marcelo Gleiser, in tomorrow’s New York Times. The article is a pretty good overview of some of the recent hand-wringing over certain areas of theoretical physics that seem, to some people, to be straying too far from experimental testability. (Frank and Gleiser mention a silly article by my old Ph.D. adviser that waxes particularly melodramatic on this subject.)
From the Times piece:
If a theory successfully explains what we can detect but does so by positing entities that we can’t detect (like other universes or the hyperdimensional superstrings of string theory) then what is the status of these posited entities? Should we consider them as real as the verified particles of the standard model? How are scientific claims about them any different from any other untestable — but useful — explanations of reality?
These entities are, it seems to me, not fundamentally different from the inside of Feynman’s brick, or from an electron for that matter. No one has ever seen an electron, or the inside of a brick, or the core of the Earth, for that matter. We believe that those things are real, because they’re essential parts of a theory that we believe in. We believe in that theory because it makes a lot of successful predictions. If string theory or theories that predict a multiverse someday produce a rich set of confirmed predictions, then the entities contained on those theories will have as much claim to reality as electrons do.
Just to be clear, that hasn’t happened yet, and it may never happen. But it’s just wrong to say that these theories represent a fundamental retreat from the scientific method, just because they contain unobservable entities. (To be fair, Frank and Gleiser don’t say this, but many other people do.) Most interesting theories contain unobservable entities!