Apparently the experimenters who found that neutrinos go faster than light have identified some sources of error in their measurements that may explain the result. The word originally went out in an anonymously-sourced blog post over at Science:
According to sources familiar with the experiment, the 60 nanoseconds discrepancy appears to come from a bad connection between a fiber optic cable that connects to the GPS receiver used to correct the timing of the neutrinos’ flight and an electronic card in a computer. After tightening the connection and then measuring the time it takes data to travel the length of the fiber, researchers found that the data arrive 60 nanoseconds earlier than assumed. Since this time is subtracted from the overall time of flight, it appears to explain the early arrival of the neutrinos. New data, however, will be needed to confirm this hypothesis.
Science is of course a very reputable source, but people are rightly skeptical of anonymously sourced information. But apparently it’s legitimate: a statement from the experimental group later confirmed the main idea, albeit in more equivocal language. They say they’ve found two possible sources of error that may eventually prove to explain the result.
Nearly all physicists (probably including the original experimenters) expected something like this to happen: it always seemed far more likely that there was an experimental error of some sort than that revolutionary new physics was occurring. If you asked them why, they’d probably trot out the old saying, “Extraordinary claims require extraordinary evidence,” or maybe the version I prefer, “Never believe an experiment until it has been confirmed by a theory.”
The way to make this intuition precise is with the language of probabilities and Bayesian inference.
Suppose that you hadn’t heard anything about the experimental results, and someone asked you to estimate the probability that neutrinos go faster than light. Your answer would probably be something like 0.000000000000000000000000000000000000000000000000001, but possibly with a lot more zeroes in it. The reason is that a century of incredibly well-tested physics says that neutrinos can’t go faster than light.
We call this number your prior probability. I’ll denote it ps (s for “superluminal,” which means “faster than light”).
Now suppose that someone asked you for your opinion about the probability that this particular group of experimenters would make a mistake in an experiment like this. (Let’s say that you still don’t know the result of the experiment yet.) I’ll call your answer pm (m for “mistake”, of course). Your answer will depend on what you know about the experimenters, among other things. They’re a very successful and reputable bunch of physicists, so pm will probably be a pretty low number, but these experiments are hard, so even if you have a lot of respect for them it won’t be incredibly low the way ps is.
Now someone tells you the result: “These guys found that neutrinos go faster than light!” The theory of probability (specifically the part often called “Bayesian inference”) gives a precise prescription for how you will update your subjective probabilities to take this information into account. I’m sure you’re dying to know the formula, so here it is:
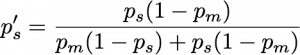
Here ps‘ means the final (posterior) probability that neutrinos go faster than light.
For any given values of the two input probabilities, you can work out your final probability. But we can see qualitatively how things are going to go without a tedious calculation. Suppose that you have a lot of respect for the experimenters, so that pm is small, and that you’re not a crazy person, so that ps is extremely small (much less than pm). Then to a good approximation the numerator in that fraction is ps and the denominator is pm + ps, which is pretty much pm. We end up with
ps‘ = ps/pm .
If, for instance, you thought there was only a one in a thousand chance that the experimenters would make a mistake, then ps‘ would be 1000 ps. That is, the experimental result makes it 1000 times more likely that neutrinos go faster than light. But you almost certainly thought that ps was much smaller than 1/1000 to begin with — it was more like 0.0000000000000000000000000000000000001 or something. So even after you bump it up by a factor 1000, it’s still small.
The situation here is exactly the same as a classic example people love to use in explaining probability theory. Suppose you take a test for some rare disease, and the test comes back positive. You know that the test only fails 1 in 1000 times. Does that mean there’s only a 0.1% chance of your being disease-free? No. If the disease is rare (your prior probability of having it was low), then it’s still low even after you get the test result. You would only conclude that you probably had the disease if the failure rate for the test was at least as low as the prior probability that you had the disease.
One sociological note: people who talk about probabilities and statistics a lot tend to sort themselves into Bayesian and non-Bayesian camps. But even those scientists who are fervently anti-Bayesian still believed that the superluminal neutrino experiment was wrong, and even those people were (by and large) not surprised by the recent news of a possible experimental error. I claim that those people were in fact unconsciously using Bayesian inference in assessing the experimental results, and that they do so all the time. There’s simply no other way to reason in the face of uncertain, probabilistic knowledge (i.e., all the time). Whether or not you think of yourself as a Bayesian, you are one.
There’s an old joke about a person who put a horseshoe above his door for good luck. His friend said, “C’mon, you don’t really believe that horseshoes bring good luck, do you?” The man replied, “No, but I hear it works even if you don’t believe in it.” Fortunately, Bayesian inference is the same way.
