That’s Nature the premier science journal, not the nature that abhors a vacuum. Check out this news feature on problems in the field.
These problems occur throughout the sciences, but psychology has a number of deeply entrenched cultural norms that exacerbate them. It has become common practice, for example, to tweak experimental designs in ways that practically guarantee positive results. And once positive results are published, few researchers replicate the experiment exactly, instead carrying out ‘conceptual replications’ that test similar hypotheses using different methods. This practice, say critics, builds a house of cards on potentially shaky foundations.
I’m not a psychologist, so I can’t be sure how much merit there is in the article’s indictments. But don’t worry — I won’t let that stop me from commenting!
The article seems to me to make three main claims:
- “Publication bias” is a serious problem — results that show something positive and surprising are much more likely to be published.
- Psychologists often use dishonest statistical methods (perhaps unintentionally).
- People don’t replicate previous results exactly.
Let’s take each in turn.
1. Publication bias.
There’s no doubt that experiments that show a positive result are more highly valued than experiments that don’t show one. It’s much better for your career to find something than to find nothing. That’s bound to lead to a certain amount of “publication bias”: the published literature will contain many more false positives than you’d naively expect, because the false positives are more likely to get published.
This problem is exacerbated by the fact that people often use the ridiculously low threshold of 95% confidence to decide whether a result is statistically significant. This means that you expect one out of every 20 tests you do to yield a false positive result. There are lots of people doing lots of tests, so of course there are lots of false positives. That’s why, according to John Ioannidis, “most published [medical] research findings are false.”
The Nature piece claims that these problems are worse in psychology than in other fields. I don’t know if that’s true or not. Some evidence from the article:
Psychology and psychiatry, according to other work by Fanelli, are the worst offenders: they are five times more likely to report a positive result than are the space sciences, which are at the other end of the spectrum. The situation is not improving. In 1959, statistician Theodore Sterling found that 97% of the studies in four major psychology journals had reported statistically significant positive results5. When he repeated the analysis in 1995, nothing had changed.
One reason for the excess in positive results for psychology is an emphasis on “slightly freak-show-ish” results, says Chris Chambers, an experimental psychologist at Cardiff University, UK. “High-impact journals often regard psychology as a sort of parlour-trick area,” he says. Results need to be exciting, eye-catching, even implausible. Simmons says that the blame lies partly in the review process. “When we review papers, we’re often making authors prove that their findings are novel or interesting,” he says. “We’re not often making them prove that their findings are true.”
Incidentally, the article has a graphic illustrating the fraction of times that papers in different disciplines quote positive results, but it doesn’t seem to support the claim that psychology is five times worse than space science:
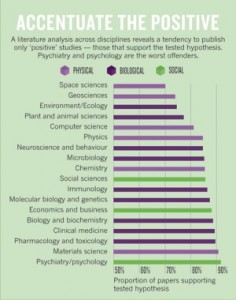
I estimate psychology is at about 93% and space science is at about 70%. That’s not a factor of 5.
2. Dishonest statistics.
Nature doesn’t use a loaded word like “dishonest,” but here’s what they claim:
Many psychologists make on-the-fly decisions about key aspects of their studies, including how many volunteers to recruit, which variables to measure and how to analyse the results. These choices could be innocently made, but they give researchers the freedom to torture experiments and data until they produce positive results.
In a survey of more than 2,000 psychologists, Leslie John, a consumer psychologist from Harvard Business School in Boston, Massachusetts, showed that more than 50% had waited to decide whether to collect more data until they had checked the significance of their results, thereby allowing them to hold out until positive results materialize. More than 40% had selectively reported studies that “worked”. On average, most respondents felt that these practices were defensible. “Many people continue to use these approaches because that is how they were taught,” says Brent Roberts, a psychologist at the University of Illinois at Urbana–Champaign.
If you deliberately choose to report data that lead to positive results and not data that lead to negative results, then you’re just plain lying about your data. The same goes for continuing to gather data, only stopping when “positive results materialize.”
Once again, I am not claiming that psychologists do this. I am claiming that if they do this, as Nature claims, it’s a very serious problem.
3. People don’t replicate previous studies.
The Nature article tells the story of the people who tried to replicate a previous study claiming to show precognition. Journals wouldn’t accept the paper detailing the failed replication. I agree with the author that this is a shame.
But the article’s concerns on this seem quite overwrought to me. They point out that most of the time people don’t try to replicate studies exactly, instead performing “conceptual replications,” in which they do something similar but not identical to what’s been done before. The author seems to think that this is a problem, but I don’t really see why. Here’s his argument:
But to other psychologists, reliance on conceptual replication is problematic. “You can’t replicate a concept,” says Chambers. “It’s so subjective. It’s anybody’s guess as to how similar something needs to be to count as a conceptual replication.” The practice also produces a “logical double-standard”, he says. For example, if a heavy clipboard unconsciously influences people’s judgements, that could be taken to conceptually replicate the slow-walking effect. But if the weight of the clipboard had no influence, no one would argue that priming had been conceptually falsified. With its ability to verify but not falsify, conceptual replication allows weak results to support one another. “It is the scientific embodiment of confirmation bias,” says Brian Nosek, a social psychologist from the University of Virginia in Charlottesville. “Psychology would suffer if it wasn’t practised but it doesn’t replace direct replication. To show that ‘A’ is true, you don’t do ‘B’. You do ‘A’ again.”
It’s true that a “conceptual replication” doesn’t directly falsify a particular result in the same way that a (failed) exact replication would. But I can’t bring myself to care that much. If a result is incorrect, it will gradually become clear that it doesn’t fit in with the pattern built up by many subsequent similar-but-not-identical experiments. The incorrect result will gradually atrophy from lack of attention, even if there’s not a single definitive refutation.
At least, that’s the way I see things working in physics, where direct replications of previous experiments are extremely uncommon.
