
Spotify has over 82 million tracks (About Spotify 2022). In the digital age, access is no longer the primary issue but rather, the ability to navigate the rather vast music library. Spotify has been working hard to simplify the listening experience through these four methods: Spotify Radio Playlists, Discover Weekly playlist, Release Radar, and your Daily Mixes. In order to curate these playlists, a recommender system is utilized. A recommender system is a “computer program that recommends some sort of resource based on algorithms that rely on some sort of user model, some sort of content model, and some means of matching the two” (IGI Global). For a music recommender, the goal is to help users “filter and discover songs according to their tastes” (Yading et. al). Moreover, “the success of a music recommender depends on its ability to predict how much a particular user will like or dislike each item” generated specifically for the said user (Laplante, p. 1). From a general music recommender system framework perspective, we will illustrate the conventional model and how studies of this model can help us understand why Camila Cabello seems to match our preferences and why the songs recommended to us are seemingly repetitive in nature.
Conducive to establishing a base of knowledge, we will refer to A Survey of Music Recommendation Systems and Future Perspectives, in which the authors posit that the success of a recommendation system depends on tracking and analyzing lots of user information.
According to the authors, there are three major domains of a music recommender system: users, items, and user-item matching algorithms.
User Step One: Profile Modeling

A user’s demographic, geographic, and psychographic information function to build the user profile. These three domains The psychological data can be divided into stable and fluid: the former being essential in long-term predictions and the latter changing potentially on an hour-to-hour basis (397).
User Step 2: Listening Experience Modeling

The authors discuss data taken from a diversified audience (16-45 years old) and depending on their level of music expertise, their expectations in music are categorized into four groups as shown above.
It is important to classify music users so that we can consider their input when thinking about how to improve a user-oriented recommendation system. Our analysis of a satisfactory recommendation system can benefit from their advice including but not limited to how much music that is interesting and unknown that is hidden in the long tail, the different types of listening behaviors, and how each of these categories accesses music.
Item Profiling
The music item is the second component of recommender systems. Dixon and others define three types of gathered information, otherwise known as metadata.

Acoustic metadata is the most used out of the three categories to discover music, also known as content-based information retrieval.
[How is this data collected?)
User-Item Matching Algorithms
There are two common types of approaches: collaborative filtering and content-based filtering.
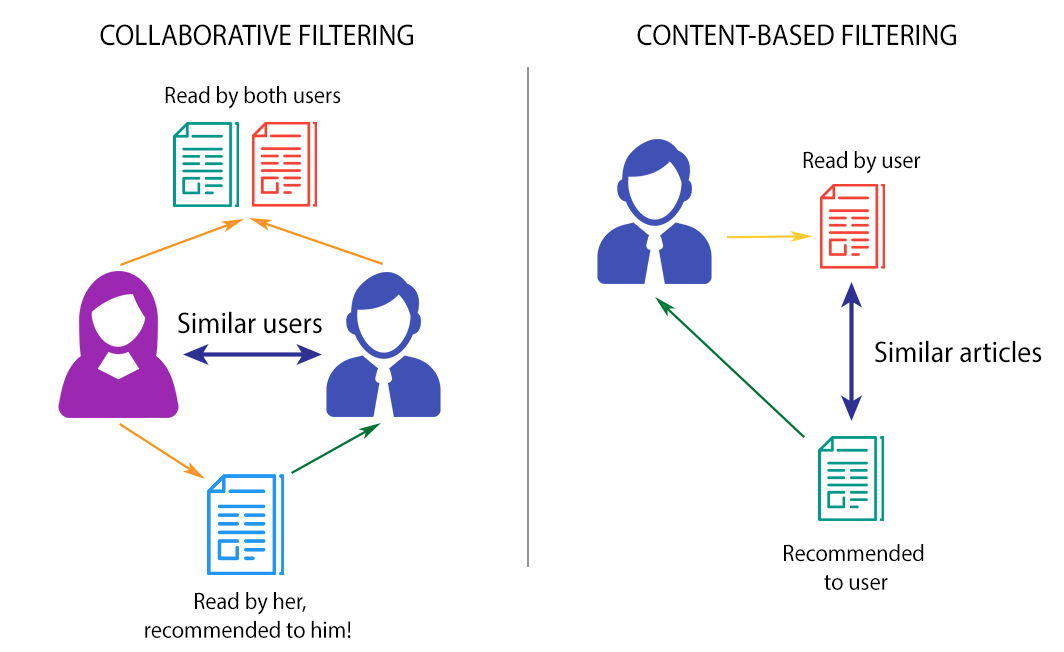
Recommendation Techniques (Doshi 2019)
Collaborative filtering, at its very essence, “assumes that if user X and user Y rate n items similarly or have similar behavior, they will rate or act on other items similarly” (Dixon et. al, p. 400). This method does not compare the items themselves but rather delivers recommendations to a set of similar users. Based on what your ‘neighbor’ likes based on similarities between the two of you, the algorithm will think you do too. The most successful version of collaborative filtering combines predicting the item based on previous ratings and using machine learning to predict user preference from previous actions. Although not widely studied, similar behaviors do not always indicate similar music tastes. There are a few pertinent limitations of collaborative filtering that are worth mentioning. A limitation of this approach includes popularity bias, where popular music usually receives more ratings and resides in the long tail, thus more likely to be recommended to the listeners. Another limitation is data sparsity, otherwise known as cold start, where few ratings are provided at an early stage, thus resulting in poor predictions.
Content/Audio/Signal-based Music Information Retrieval, on the other hand, makes a prediction for the user by analyzing the song tracks. This method focuses on specifically what songs the user has liked in the past rather than on the speculation and analysis of the user itself. Adiyansjah and others postulate that convolutional recurrent neural networks (CRNNs) are employed to look at “similarities between high-level music features …[like chords and beats] and recurrent neural networks (RNNs) were designed to work with time-series data especially for temporal sequence prediction problems [like word and paragraph sequences in natural language processing” (100). This method has developed tremendously and will increase in effectiveness and efficiency as technology progresses in terms of systematically comparing songs but how do we measure whether or not a user agrees with the verdict and likes the new song?
So now what?
Now that we have a better understanding of how a recommendation system works, where do we go from here? In our next section, we will continue our discussion on how to recalibrate our expectations of what a recommendation system will look like and compare alternative methods to support our mission to improve our Explore Page.